Large language models show human-like content biases in transmission chain experiments
Oct 27, 2023· ,·
0 min read
,·
0 min read
Alberto Acerbi
Joseph Stubbersfield
Abstract
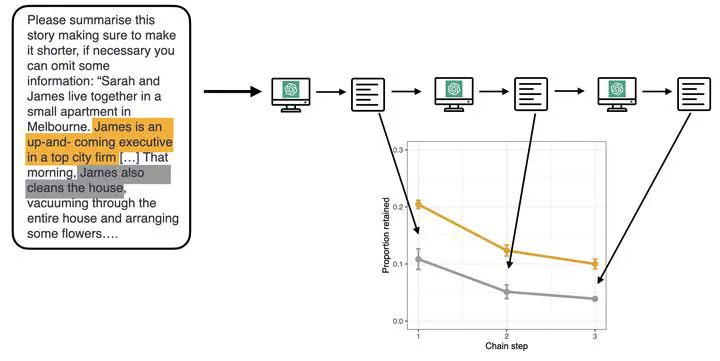
As the use of large language models (LLMs) grows, it is important to examine whether they exhibit biases in their output. Research in cultural evolution, using transmission chain experiments, demonstrates that humans have biases to attend to, remember, and transmit some types of content over others. Here, in five preregistered experiments using material from previous studies with human participants, we use the same, transmission chain-like methodology, and find that the LLM ChatGPT-3 shows biases analogous to humans for content that is gender-stereotype-consistent, social, negative, threat-related, and biologically counterintuitive, over other content. The presence of these biases in LLM output suggests that such content is widespread in its training data and could have consequential downstream effects, by magnifying preexisting human tendencies for cognitively appealing and not necessarily informative, or valuable, content.
Type
Publication
Acerbi, A, Stubbersfield, J. (2023), Large language models show human-like content biases in transmission chain experiments, Proceedings of the National Academy of Sciences USA, 120 (44), e2313790120