Robustness of emotion extraction from 20th century English books
Abstract
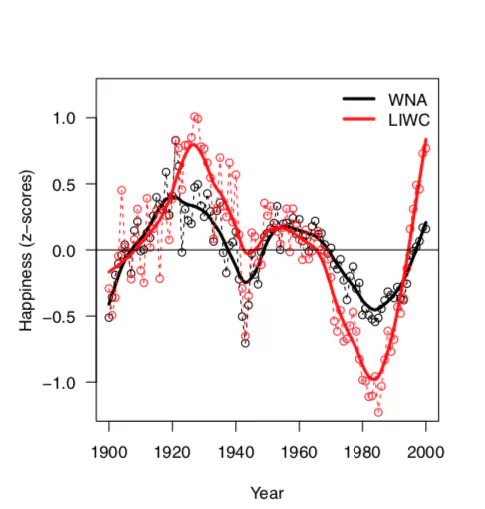
In this paper, we test the robustness of emotion extraction from English language books published in the 20th century. Our analysis is performed on a sample of the 8 million digitized books available in the Google Books Ngram corpus by applying three independent emotion detection tools: WordNet Affect, Linguistic Inquiry and Word Count, and a recently proposed ‘Hedonometer’ method. We also assess the statistical robustness of the extracted patterns as well as their outputs on specific parts of speech. The analysis confirms three main results: the existence of recognizable periods of positive and negative ‘literary affect’ from 1900 to 2000, a general decrease in the usage of emotion-related words in printed books that lasts at least until the 1980s, and, finally, a divergence between American and British books, with the former using more emotion-related words from the 1960s.
Type
Publication
Acerbi A., Lampos V., Bentley R. A. (2013), Robustness of emotion extraction from 20th century English books, in IEEE BigData 2013 Proceedings, pp. 1 – 8