Quantitative analysis of large scale cultural data
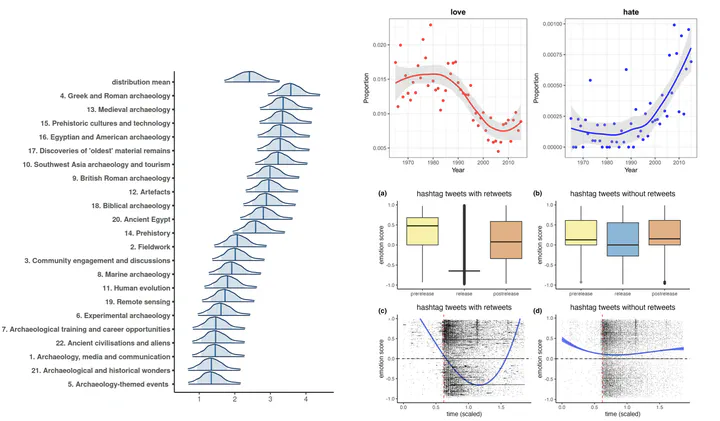
I am interested in analysing large, naturally occurring datasets to investigate human cultural dynamics, especially in modern societies. By “naturally occurring,” I mean datasets that were not created specifically for research purposes (like surveys or census data) but instead represent traces, often digital, of human activity, such as books, songs, movies, or social media interactions.
For example, I have used:
dog registrations data to examine whether breed popularity is driven by individual preferences or social influence;
data from Google Books, the Gutenberg project, and English language songs to uncover a general decline in the expression of emotions, mostly due to a decrease in positive emotions;
baby names records and last.fm playlists to test whether changes in the popularity of cultural traits reveal the learning biases involved;
folktales databases, to explore whether the complexity of stories correlates with the population size of the societies in which they circulate.
More recently, I have analysed social media data, studying topics such as the spread of the spread of voter frauds theories about the 2022 U.S. election; the spread of archological content on Twitter/X, or the social media response to Netflix’s Our Planet Documentary.
This line of work overlaps with what is often called digital humanities, computational humanities, or cultural analytics in sociology. What makes my research cohesive is the use of methods and theories from cultural evolution to generate and test hypotheses with these data. To put it in a slogan: “Big data need big theory.”