Role of Neutral evolution in word turnover during centuries of English word popularity
Nov 2, 2017·, ,,·
0 min read
,,·
0 min read
Damian Ruck
R. Alexander Bentley
Alberto Acerbi
Philip Garnett
Daniel J. Hruschka
Abstract
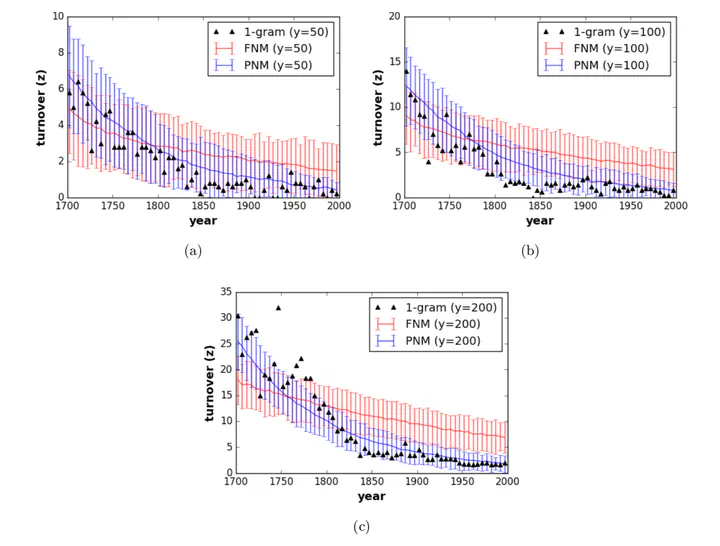
Here, we test Neutral models against the evolution of English word frequency and vocabulary at the corpus scale, as recorded in annual word frequencies from three centuries of English lan- guage books. Against these data, we test both static and dynamic predictions of two neutral models, including the relation between corpus size and vocabulary size, frequency distributions, and turnover within those frequency distributions. Although a commonly used Neutral model fails to replicate all these emergent properties at once, we find that a modi fied two-stage Neutral model does replicate the static and dynamic properties of the corpus data. This two-stage model is meant to represent a relatively small corpus of English books, analogous to a `canon’, sampled by an exponentially increasing corpus of books among the wider population of authors. More broadly, this model - a smaller neutral model within a larger neutral model - could represent more broadly those situations where mass attention is focused on a small subset of the cultural variants.
Type
Publication
Ruck, D., Bentley, R. A., Acerbi, A., Garnett, P., Hruschka, D. J. (2017), Role of Neutral evolution in word turnover during centuries of English word popularity, Advances in Complex Systems, 20 (6-7), 1750012