Chapter 8 Rogers’ Paradox
The previous chapters all concerned cultural evolutionary dynamics: how different biases and transmission pathways affect the frequency of cultural traits in a population over time. Equally important, though, is to step back and consider where the possibility of culture came from in the first place. That is, we need to also consider the evolution of culture, and the evolution of cultural evolution.
The most basic question we can ask here is why a capacity for social learning (learning from others) evolved, relative to individual learning (learning directly from the environment, on one’s own). An intuitive answer to this question is that social learning is less costly than individual learning. Imagine trying out different foods, some of which may be poisonous. One could try each one, and see if they make you ill. A less risky strategy would be to observe one’s neighbour, and eat what they are eating. Unless they look sickly all the time, this will likely lead to a palatable (and evolutionarily adaptive) choice. Consequently, social learning should increase the mean adaptation of a population.
However, this intuition can be misleading. This was shown in 1988 by Alan Rogers in a now-classic model of the evolution of social learning (Rogers (1988)). This model is often called “Rogers’ paradox,” because it shows that under certain conditions, social learning does not lead to increased adaptation, even when it is less costly than individual learning. More precisely, the mean fitness of a population containing social learners does not exceed the mean fitness of a population composed entirely of individual learners. Here we will recapitulate Rogers’ mathematical model in an individual-based simulation, to see when and why this counter-intuitive result holds.
8.1 Modelling Rogers’ Paradox
In Rogers’ model there are \(N\) individuals. Each individual has a fixed learning strategy: they are either an individual learner, or a social learner. Each individual also exhibits a behaviour, which we will represent, as the traits in the previous chapter with an integer (e.g. “5,” or “32”). (“Trait” and “behaviour” are often used interchangeably in cultural evolution literature.) There is also an environmental state, \(E\), which is also represented with an integer. When an individual’s behaviour matches the environment, they receive increased fitness, compared to when it does not match. A match might represent ‘palatable food,’ while a mismatch might represent ‘poisonous food.’
In each generation, individual learners directly sample the environment, and have a probability \(p\) of acquiring the ‘correct,’ adaptive behaviour that matches the environment (and therefore a probability \(1-p\) of adopting the incorrect, maladaptive behaviour). Social learners choose a member of the previous generation at random and copy their behaviour, just like for unbiased transmission considered in Chapter 1.
Unlike previous models, we are interested here not in the behaviours or traits, but in how the learning strategies evolve over time. We therefore want to track the proportion of social learners in the population, which we call \(p_{SL}\) (with \(1-p_{SL}\) being the proportion of individual learners). We assume these strategies are inherited (perhaps genetically, possibly culturally) from parent to offspring, and are affected by the fitness of the bearers of the strategies. Hence we need to specify fitness parameters.
Each individual starts with a baseline fitness, \(w\). This is typically set at 1, to avoid tricky-to-handle negative fitnesses. Individuals who have behaviour that matches the environment receive a fitness boost of \(+b\). Individuals who have behaviour that does not match the environment receive a fitness penalty of \(-b\). Explicit in the above verbal outline is that social learning is less costly than individual learning. Therefore, individual learners receive a fitness cost of \(-b*c\), and social learners receive a fitness cost of \(-b*s\), where \(c>s\). For simplicity, we can set \(s=0\) (social learning is free) and set \(c>0\), so we only have to change one parameter.
The fitness of each individual is then totted up based on the above, and the next generation is created. Each individual reproduces in proportion to the fitness of their strategy, relative to other strategies.
We also assume some mutation during reproduction. With probability \(\mu\), the new individual ‘mutates’ to the other learning strategy. Because we are interested here in how social learning evolves from individual learning, we start with a first generation entirely made up of individual learners. Social learning then appears from the second generation onwards via mutation.
Finally, Rogers was interested in the effect of environmental change. Each generation, there is a probability \(u\) of the environment changing to a new state. In Rogers’ original model, the environment flipped between the same two states, back and forth. However, this is problematic when environmental change is very fast, because an individual with out-dated behaviour can receive a fitness benefit if the environment flips back to the previous state. Hence we assume that when environments change, they change to a new value never previously experienced by any individual.
This is a complex model but let’s go step by step. First we create and initialise tibbles to store the output and the population of individuals, just like in previous chapters. The output here needs to be big enough to store data from \(r_{max}\) runs and \(t_{max}\) generations, like before. We then need to create NA placeholders for \(p_{SL}\) (the proportion of social learners) and \(W\) (the mean population fitness). The population tibble stores the characteristics of the individuals: learning strategy (‘individual’ or ‘social’), behaviour (initially all NA) and fitness (initially all NA). Finally, we initialise the environment \(E\) at zero, which will subsequently increment, meaning that the environment changes.
library(tidyverse)
N <- 100
r_max <- 1
t_max <- 10
# Create the output tibble
output <- tibble(generation = rep(1:t_max, r_max),
run = as.factor(rep(1:r_max, each = t_max)),
p.SL = as.numeric(rep(NA, t_max * r_max)),
W = as.numeric(rep(NA, t_max * r_max)))
# Create the population tibble
population <- tibble(learning = rep("individual", N),
behaviour = rep(NA, N),
fitness = rep(NA, N))
# Initialise the environmental state to 0
E <- 0Now let’s go through each event that happens during a single generation. Later we will put it all inside a loop. It’s useful to write out the events that we need:
- Social learning
- Individual learning
- Calculate fitnesses
- Store population characteristics in output tibble
- Reproduction
- Potential environmental change
First, social learning. The following code picks random individuals from the previous_population tibble (which we have yet to create, but will do later), to put into the social learner individuals in the current population tibble. This is similar to what we did in the previous chapters. It only does this if there is at least one social learner. As noted above, we start in the first generation with all individual learners and no social learners, so this will not be fulfilled until the second generation. For now, nothing happens.
if (sum(population$learning == "social") > 0) {
population$behaviour[population$learning == "social"] <-
sample(previous_population$behaviour, sum(population$learning == "social"), replace = TRUE)
}The following code implements individual learning. This does apply to the first generation. We first create a vector of TRUE and FALSE values dependent on \(p\), the probability of individual learning resulting in a correct match with the environment. With this probability, individual learners have their behaviour set to the correct \(E\) value. Otherwise, they are given the incorrect behaviour \(E-1\). Note the use of the ! before learn_correct to give a match when this vector is FALSE (i.e. they do not learn the correct behaviour).
learn_correct <- sample(c(TRUE, FALSE), N, prob = c(p, 1 - p), replace = TRUE)
population$behaviour[learn_correct & population$learning == "individual"] <- E
population$behaviour[!learn_correct & population$learning == "individual"] <- E - 1Now we obtain the fitnesses for each individual. First we give everyone the baseline fitness, \(w\). Then we add or subtract \(b\), based on whether the individual has the correct or incorrect behaviour. Finally we impose costs, which are different for social and individual learners.
# Baseline fitness
population$fitness <- w
# For individuals with behaviour matched to the environment, add b
population$fitness[population$behaviour == E] <-
population$fitness[population$behaviour == E] + b
# For individuals with behaviour not matched to the environment, subtract b
population$fitness[population$behaviour != E] <-
population$fitness[population$behaviour != E] - b
# Impose cost b*c on individual learners:
population$fitness[population$learning == "individual"] <-
population$fitness[population$learning == "individual"] - b*c
# Impose cost b*s (i.e. 0) on social learners:
population$fitness[population$learning == "social"] <-
population$fitness[population$learning == "social"] - b*s The fourth stage is recording the resulting data into the output tibble. First we calculate \(p_{SL}\) as the number of social learners divided by the total population size. Then we calculate \(W\), the mean fitness in the entire population. All of these are done with the standard R mean command.
output[output$generation == t & output$run == r, ]$p_SL <- mean(population$learning == "social")
output[output$generation == t & output$run == r, ]$W <- mean(population$fitness)The fifth stage is reproduction. Here we put the current population tibble into a new tibble, called previous_population, as we have done before. This acts as both a record to now calculate fitnesses, as well as a source of demonstrators for the social learning stage we covered above. After doing this, we reset the behaviour and fitness of the current population. We then over-write the learning strategies based on fitness.
First we get fitness_IL, the fitness of individual learners relative to the fitness of the entire population (assuming there are any individual learners, otherwise we set this to zero). This then serves as the probability of setting new individuals as individual learners in the next generation. We use gain the function sample() to create mutation, denoting the probability of an individual mutating their learning strategy. Finally, we change the learning strategy of the ‘mutant’ individuals. Notice we need to create a temporary new tibble, previous_poulation2, to avoid to mutate twice the individuals that are changed from individual to social learning in the first mutation instruction.
previous_population <- population
population$behaviour <- NA
population$fitness <- NA
# Relative fitness of individual learners (if there are any)
if (sum(previous_population$learning == "individual") > 0) {
fitness_IL <- sum(previous_population$fitness[previous_population$learning == "individual"]) /
sum(previous_population$fitness)
} else {
fitness_IL <- 0
}
# Create the new population
population$learning <- sample(c("individual", "social"), size = N,
prob = c(fitness_IL, 1 - fitness_IL), replace = TRUE)
# Also add mutation, chance of switching learning types
mutation <- sample(c(TRUE, FALSE), N, prob = c(mu, 1 - mu), replace = TRUE)
# Store current population in a tibble to avoid mutating twice
previous_population2 <- population
# If an individual is an individual learner plus mutation, then they're a social learner
population$learning[previous_population2$learning == "individual" & mutation] <- "social"
# If an individual is a social learner plus mutation, then they're an individual learner
population$learning[previous_population2$learning == "social" & mutation] <- "individual" The final stage is the easiest. With probability \(u\), we increment the environmental state \(E\) by one. Otherwise, it stays as it is. To do this we pick a random number between 0 and 1 using the \(runif\) command, and if \(u\) exceeds this, we increment \(E\).
if (runif(1) < u) E <- E + 1That covers the six stages that occur in each generation. We can now put them all together into a loop tracking runs, and a loop tracking generations. We can also put all this inside a function. This should all be familiar from previous chapters. Almost all the code is taken from above, and we numbered the different stages (you can find the comments to the specific lines of codes in the chunks above). We also add a parameter check at the start, to make sure that we don’t get negative fitnesses. This uses the new function stop(), that tells R to terminate the execution of the function, and print on screen the message in the parenthesis. Another novelty is that we already set some of the parameters (\(w\), \(b\) and \(s\)) in the function call. In this way, the parameters are set to these default values if not specified when the function is called. The other parameters need to be instead specified.
rogers_model <- function(N, t_max, r_max, w = 1, b = 0.5, c, s = 0, mu, p, u) {
# Check parameters to avoid negative fitnesses
if (b * (1 + c) > 1 || b * (1 + s) > 1) {
stop("Invalid parameter values: ensure b*(1+c) < 1 and b*(1+s) < 1")
}
# Create output tibble
output <- tibble(generation = rep(1:t_max, r_max),
run = as.factor(rep(1:r_max, each = t_max)),
p_SL = as.numeric(rep(NA, t_max * r_max)),
W = as.numeric(rep(NA, t_max * r_max)))
for (r in 1:r_max) {
# Create a population of individuals
population <- tibble(learning = rep("individual", N),
behaviour = rep(NA, N), fitness = rep(NA, N))
# Initialise the environment
E <- 0
for (t in 1:t_max) {
# 1. Social learning
if (sum(population$learning == "social") > 0) {
population$behaviour[population$learning == "social"] <-
sample(previous_population$behaviour, sum(population$learning == "social"), replace = TRUE)
}
# 2. individual learning
learn_correct <- sample(c(TRUE, FALSE), N, prob = c(p, 1 - p), replace = TRUE)
population$behaviour[learn_correct & population$learning == "individual"] <- E
population$behaviour[!learn_correct & population$learning == "individual"] <- E - 1
# 3. Calculate fitnesses
population$fitness <- w
population$fitness[population$behaviour == E] <-
population$fitness[population$behaviour == E] + b
population$fitness[population$behaviour != E] <-
population$fitness[population$behaviour != E] - b
population$fitness[population$learning == "individual"] <-
population$fitness[population$learning == "individual"] - b*c
population$fitness[population$learning == "social"] <-
population$fitness[population$learning == "social"] - b*s
# 4. Store population characteristics in output
output[output$generation == t & output$run == r, ]$p_SL <-
mean(population$learning == "social")
output[output$generation == t & output$run == r, ]$W <-
mean(population$fitness)
# 5. Reproduction
previous_population <- population
population$behaviour <- NA
population$fitness <- NA
if (sum(previous_population$learning == "individual") > 0) {
fitness_IL <- sum(previous_population$fitness[previous_population$learning == "individual"]) /
sum(previous_population$fitness)
} else {
fitness_IL <- 0
}
population$learning <- sample(c("individual", "social"), size = N,
prob = c(fitness_IL, 1 - fitness_IL), replace = TRUE)
mutation <- sample(c(TRUE, FALSE), N, prob = c(mu, 1 - mu), replace = TRUE)
previous_population2 <- population
population$learning[previous_population2$learning == "individual" & mutation] <- "social"
population$learning[previous_population2$learning == "social" & mutation] <- "individual"
# 6. Potential environmental change
if (runif(1) < u) E <- E + 1
}
}
# Export data from function
output
}Now we can run the simulation for \(10\) runs, and \(200\) generations, with a population of \(1000\) individuals. The other parameters we set are the cost associated to individual learning (c = 0.9); the mutation rate, i.e. the probability that an individual that inherit learning strategy (individual or social) will switch to the other (mu = 0.001); the accuracy of individual learning (p = 1); and, finally, the probability of environmental change (u = 0.2). We will later explore other values of these parameters, but feel free to change them and see what happens!
data_model <- rogers_model(N = 1000, t_max = 200, r_max = 10, c = 0.9, mu = 0.01, p = 1, u = 0.2)You can inspect the data_model tibble, but so much data is hard to make sense of. Let’s write a plotting function like in previous chapters. The only difference from our usual plot_multiple_runs() is that instead of plotting the frequency of traits, we want to visualise \(p_{SL}\), the frequency of social learners, so we
plot_multiple_runs_p_SL <- function(data_model) {
ggplot(data = data_model, aes(y = p_SL, x = generation)) +
geom_line(aes(colour = run)) +
stat_summary(fun = mean, geom = "line", size = 1) +
ylim(c(0, 1)) +
theme_bw() +
labs(y = "proportion of social learners")
}
plot_multiple_runs_p_SL(data_model)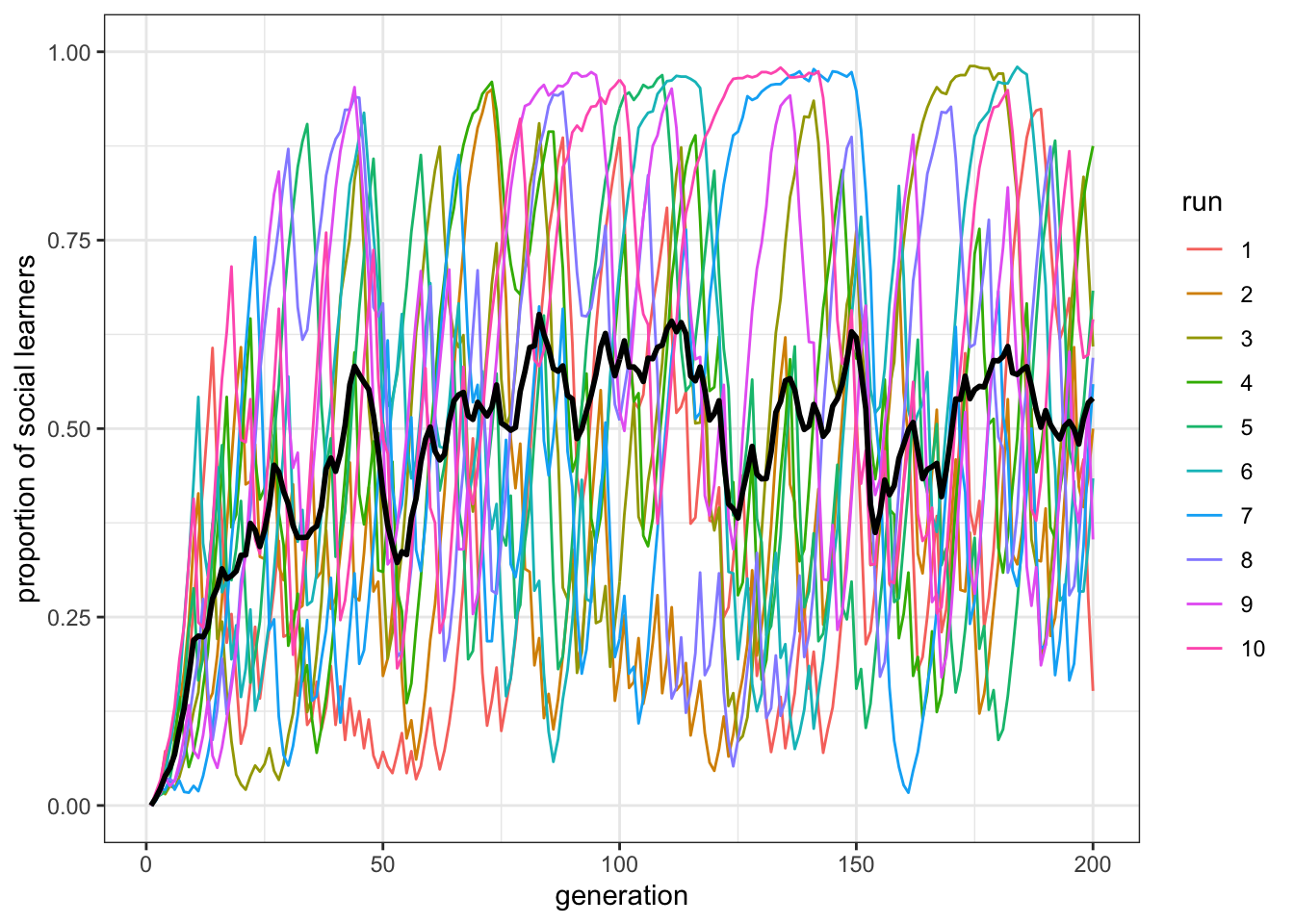
Figure 8.1: On average the proportion of social learners fluctuates around \(0.5\) (black line). However, individual runs have a larger spread around this mean (overlapping colored runs).
Here we can see that, for these parameter values, the mean proportion of social learners quickly goes to \(0.5\), but then remains fluctuating around this value. However, each run is quite erratic, with a large spread. More important for our understanding of Rogers’ paradox, however, is the mean fitness of the population, and how this compares with a population entirely composed of individual learners. Consequently, we need to plot the mean population fitness over time. This is W in the output of the rogers_model() function. The function below plots this, along with a dotted line denoting the fitness of an individual learner, which by extension will be the same as the mean fitness of a population entirely composed of individual learners. We do not need to extract this from the output of the simulation: the fitness of individual learners is fixed, known a-priori, and can be calculated knowing the values of some of the parameters of the simulation. There are a few new elements in the plotting functions. First, we want to pass to the function, together with the data_model tibble, some other information on the parameters of out simulations, so that that fitness line for individual learners can be draw. As in the main rogers_model() function, w and b are hard coded, and we need to specify c and p. Second, we use the function geom_hline(). This is another ggplot ‘geom’ that plots, as the name suggest, an horizontal line that intercept the y axis where indicated by yintervept, in our case the fitness of individual learners. Finally, we set the upper limit of the y axis to NA, which ggplot interprets as the limit from the range of the data.
plot_W <- function(data_model, w = 1, b = 0.5, c, p) {
ggplot(data = data_model, aes(y = W, x = generation)) +
geom_line(aes(color = run)) +
stat_summary(fun = mean, geom = "line", size = 1) +
geom_hline(yintercept = w + b * (2 * p - c - 1), linetype = 2) +
ylim(c(0, NA)) +
theme_bw() +
labs(y = "mean population fitness")
}
plot_W(data_model, c = 0.9, p = 1)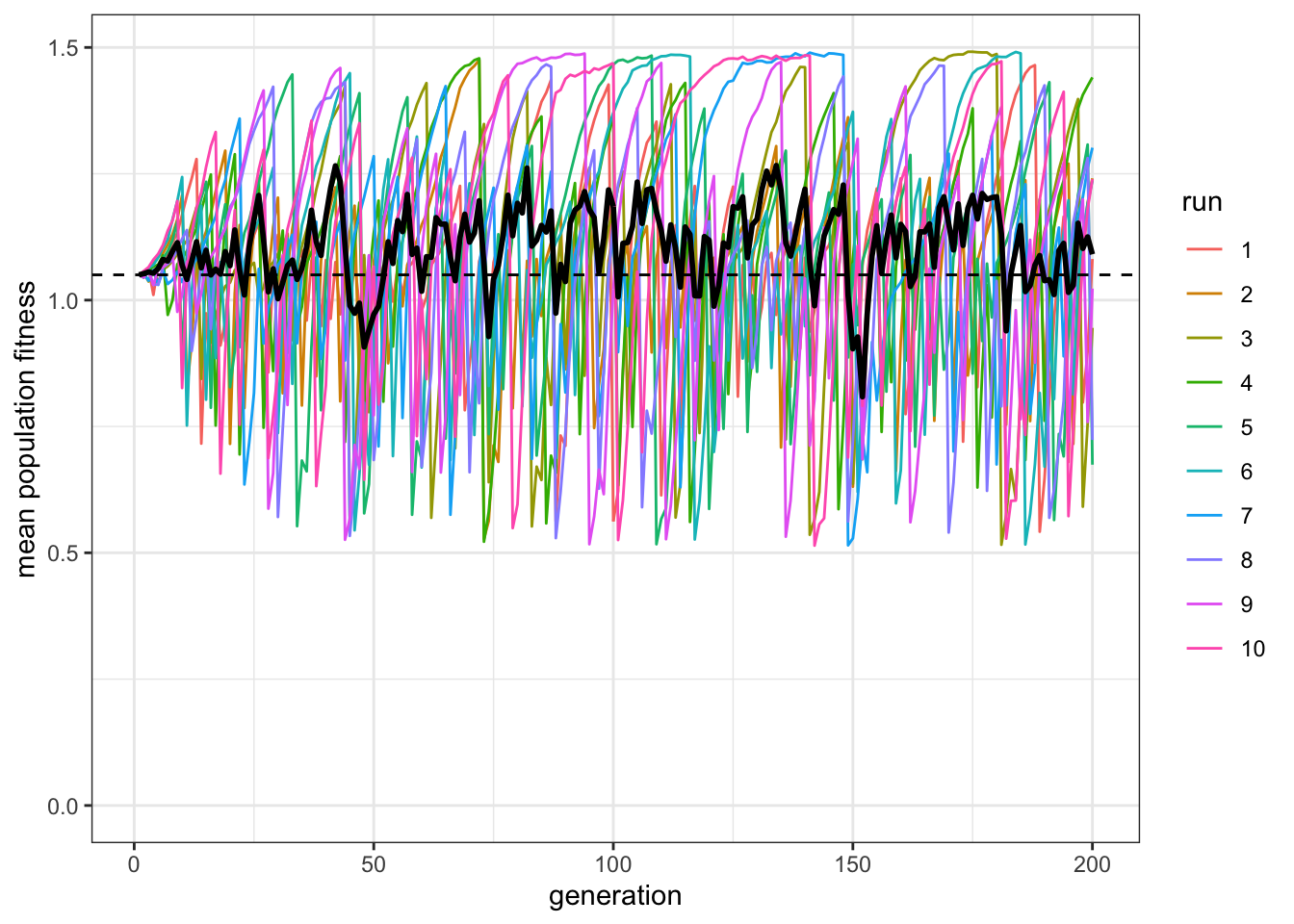
Figure 8.2: Populations with roughly 50% social learners have on average the same fitness (black line) as populations with only individual learners (dashed line). Even though populations with social learners sometimes exceed the average fitness of all-individual learner populations they also sometimes fall far below it.
This is Rogers’ paradox. Even though social learning is less costly than individual learning (i.e. \(s<c\)), our population of roughly \(50\%\) social learners do not consistently exceed the dotted line that indicates the fitness of a population of individual learners. Social learning does not increase adaptation. This also runs counter to the common claim that culture - with social learning at its heart - has been a key driver of our species’ ecological success.
The reason for this result is that social learning is frequency-dependent in a changing environment. Individual learners undergo costly individual learning and discover the correct behaviour, initially doing well. Social learners then copy that behaviour, but at lower cost. Social learners therefore then do better than, and outcompete, individual learners. But when the environment changes, the social learners do badly, because they are left copying outdated behaviour. Individual learners then do better, because they can detect the new environmental state. Individual learners increase in frequency, and the cycle continues. This is what the large oscillations of the single runs show. Analytically, it can be shown that they reach an equilibrium at which the frequency of social and individual learners is the same but, by definition, this equilibrium must have the same mean fitness as a population entirely composed of individual learners. Hence, the ‘paradox.’
To explore this further, we can alter the parameters. First, we can reduce the cost of individual learning, from \(c=0.9\) to \(c=0.4\).
data_model <- rogers_model(N = 1000, t_max = 200, r_max = 10, c = 0.4, mu = 0.01, p = 1, u = 0.2)
plot_multiple_runs_p_SL(data_model)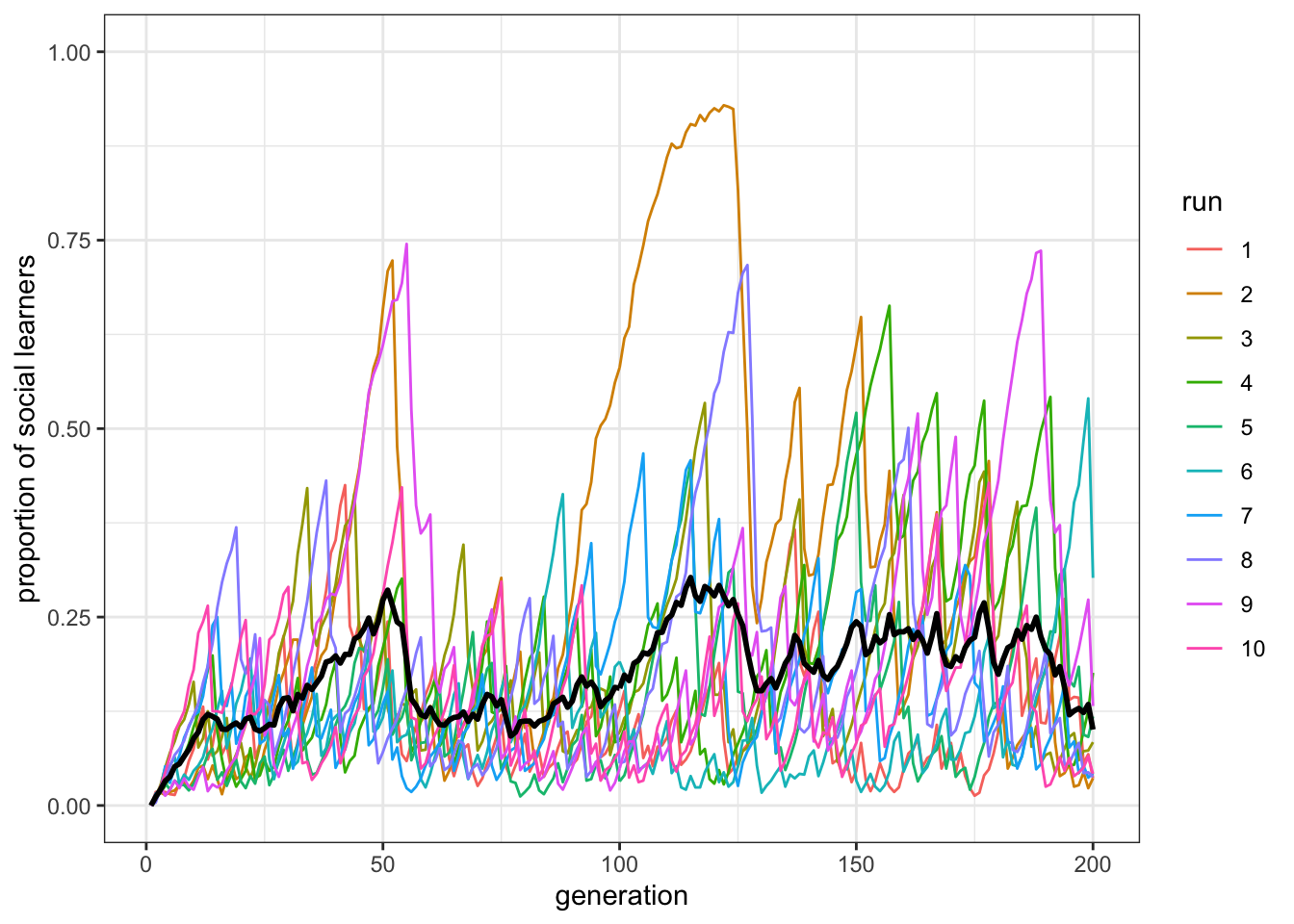
Figure 8.3: There are fewer social learners in a population where the cost of individaul learning is lower.
plot_W(data_model, c = 0.4, p = 1)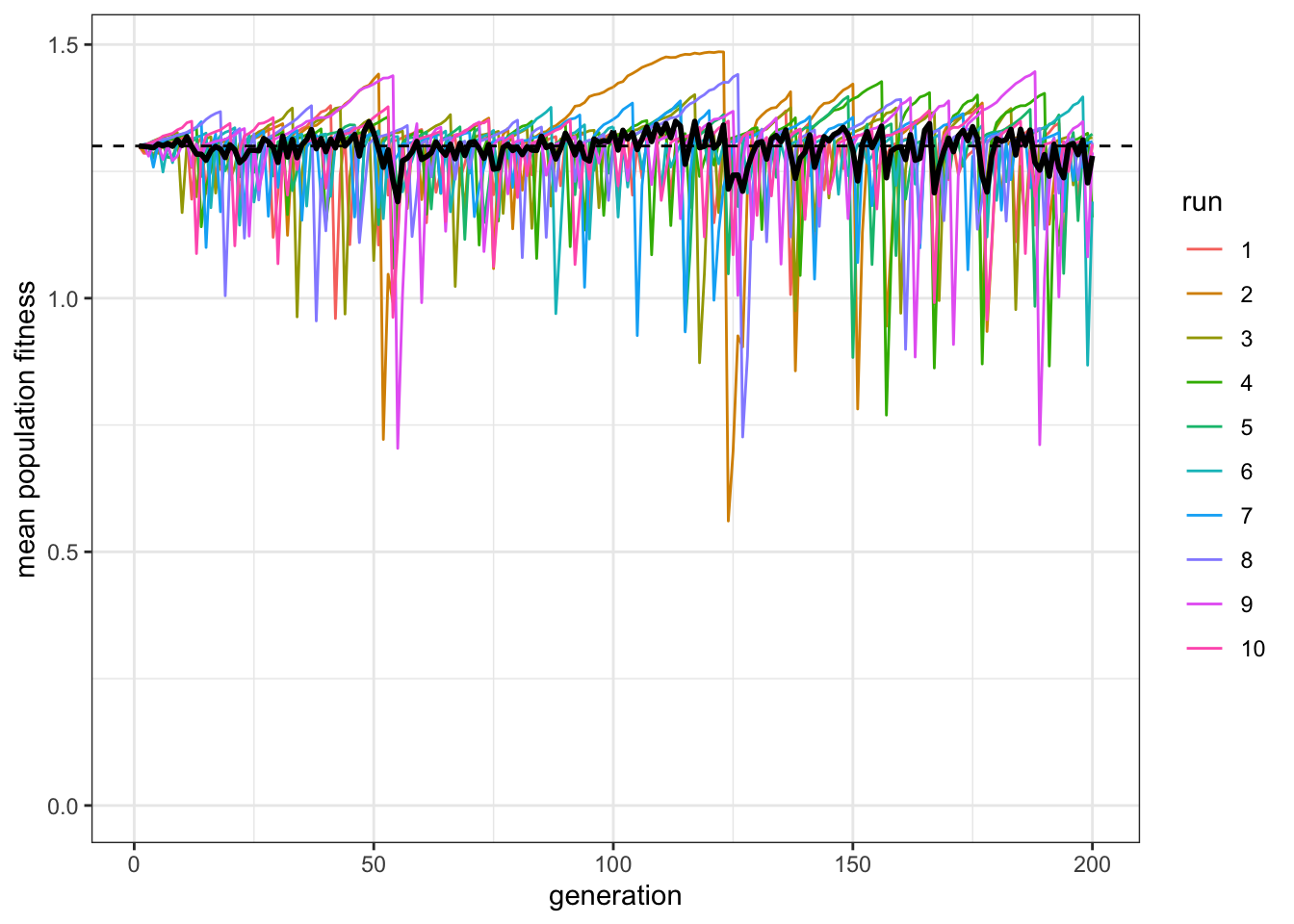
Figure 8.4: The fitness of the mixed population remains equal to the fitness of individual learners in a population where the cost of individaul learning is lower.
As we might expect, this reduces the proportion of social learners, by giving individual learners less of a penalty for doing their individual learning. Also as expected, the paradox remains. In fact it is even more obvious, given that there are many more individual learners.
We can also reduce the accuracy of individual learning, reducing \(p\) from \(1\) to \(0.7\).
data_model <- rogers_model(N = 1000, t_max = 200, r_max = 10, c = 0.9, mu = 0.01, p = 0.7, u = 0.2)
plot_multiple_runs_p_SL(data_model)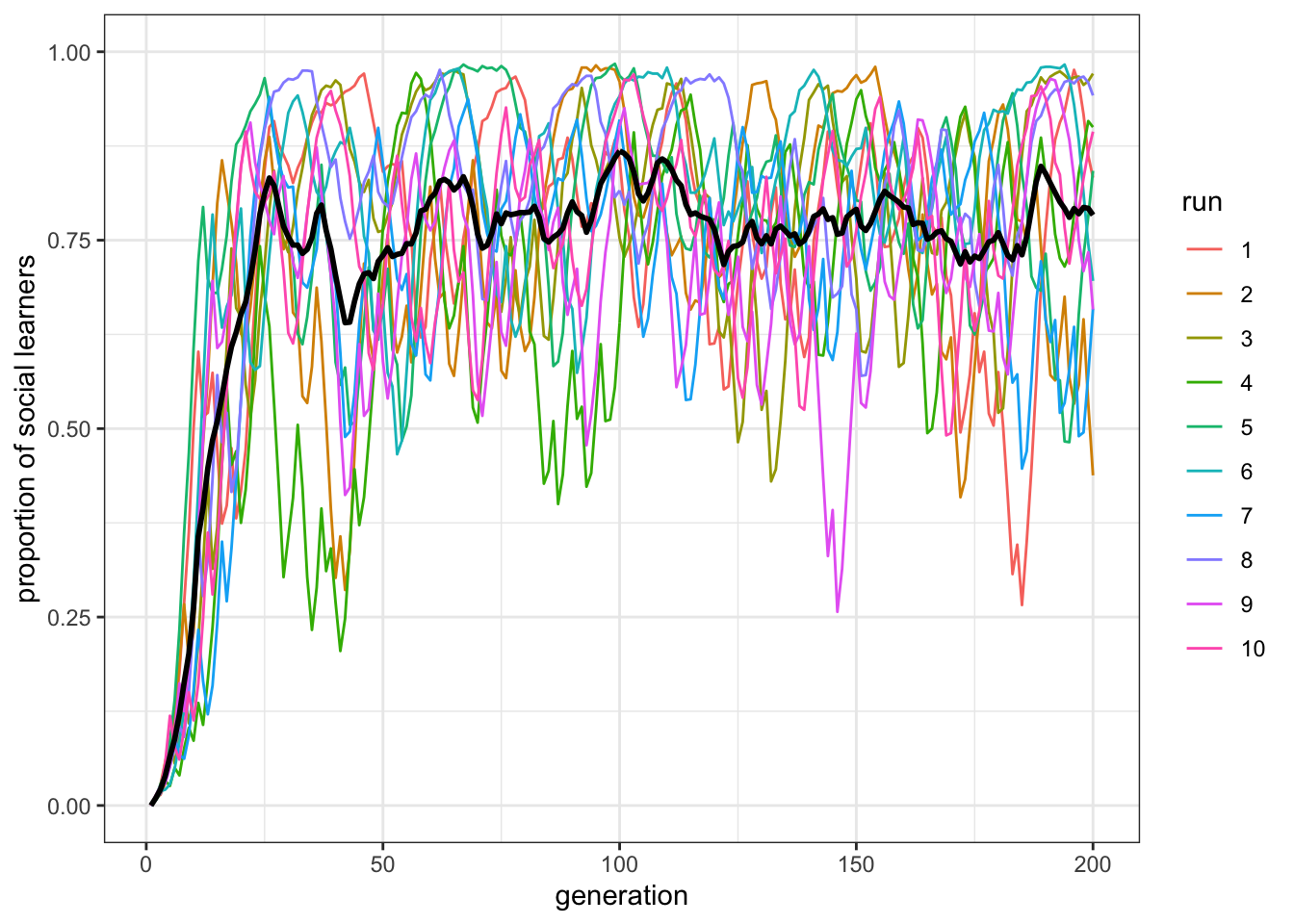
Figure 8.5: When individual learning is less accurate, there are more social learners in populations.
plot_W(data_model, c = 0.9, p = 0.7)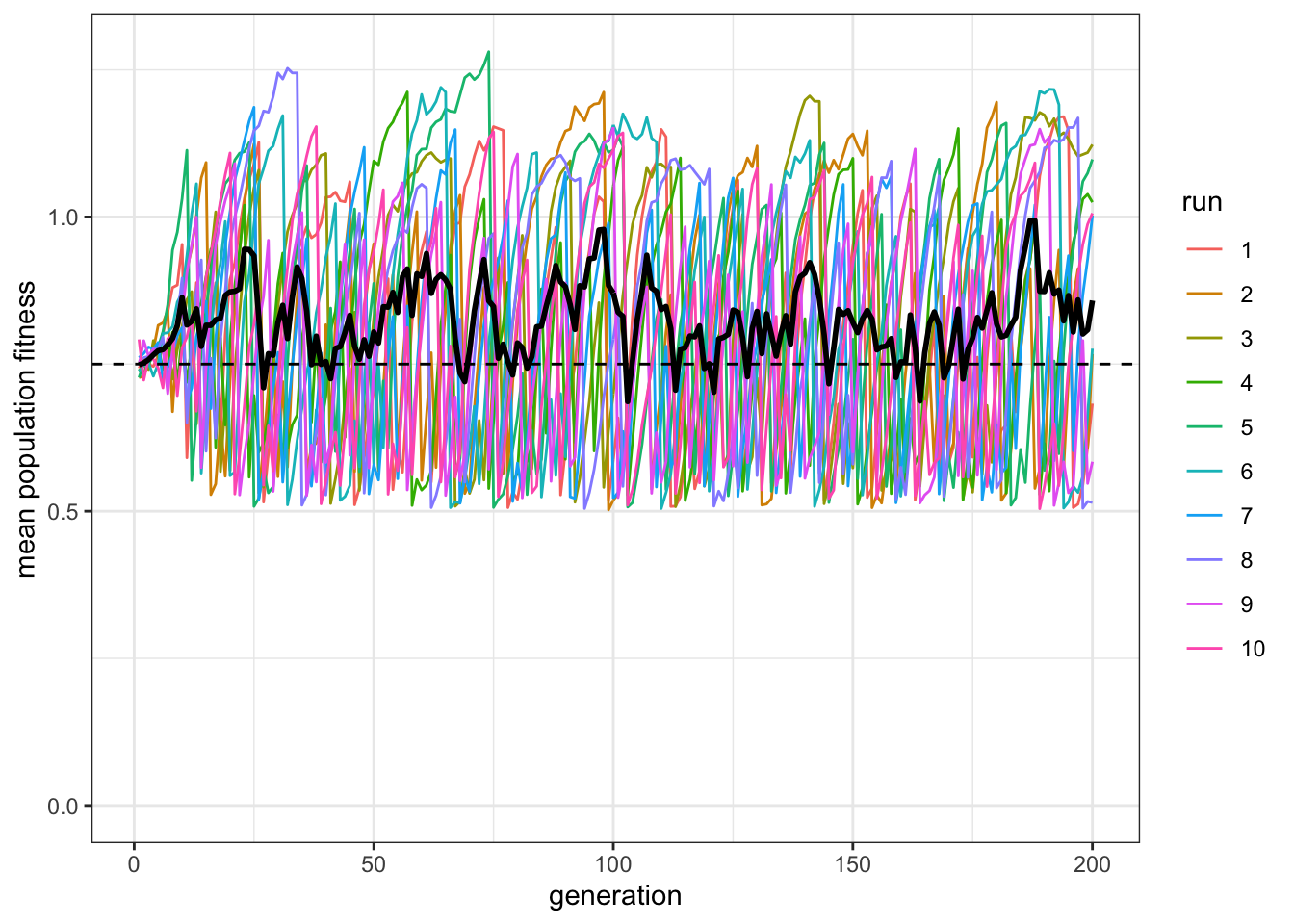
Figure 8.6: Even when individual learning is more accurate, the average fitness of mixed populations is close to the fitness of pure individual learners.
Now there are a majority of social learners. Yet the paradox remains: the mostly social learners still do not really exceed the pure individual learning fitness line.
If our explanation above is correct, then making the environment constant should remove the paradox. If the environment stays the same, then behaviour can never be outdated, and individual learners never regain the upper hand. Setting \(u=0\) shows this.
data_model <- rogers_model(N = 1000, t_max = 200, r_max = 10, c = 0.9, mu = 0.01, p = 1, u = 0)
plot_multiple_runs_p_SL(data_model)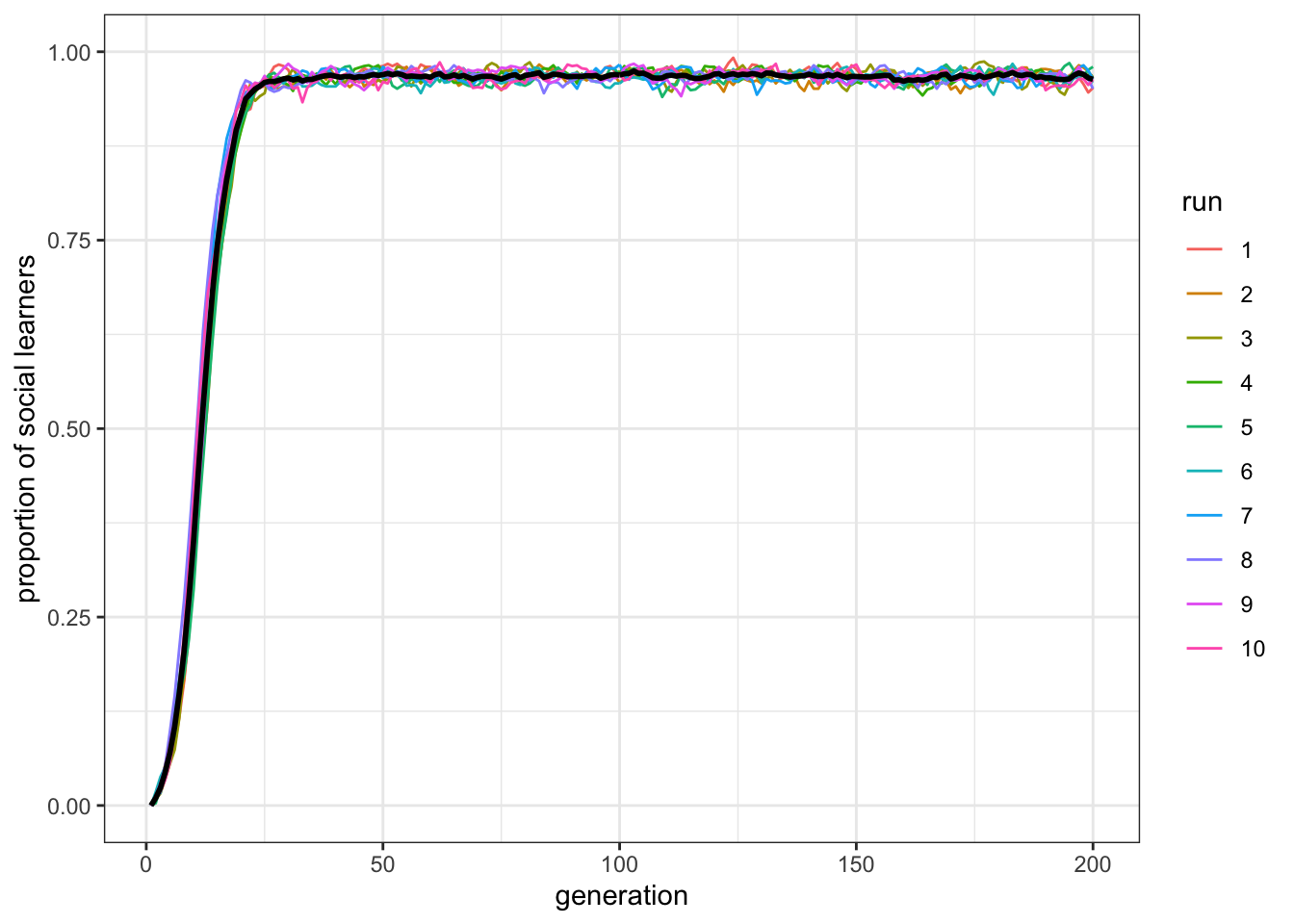
Figure 8.7: When the environment is unchanging, social learners will outperform individual learners and take over in populations.
plot_W(data_model, c = 0.9, p = 1)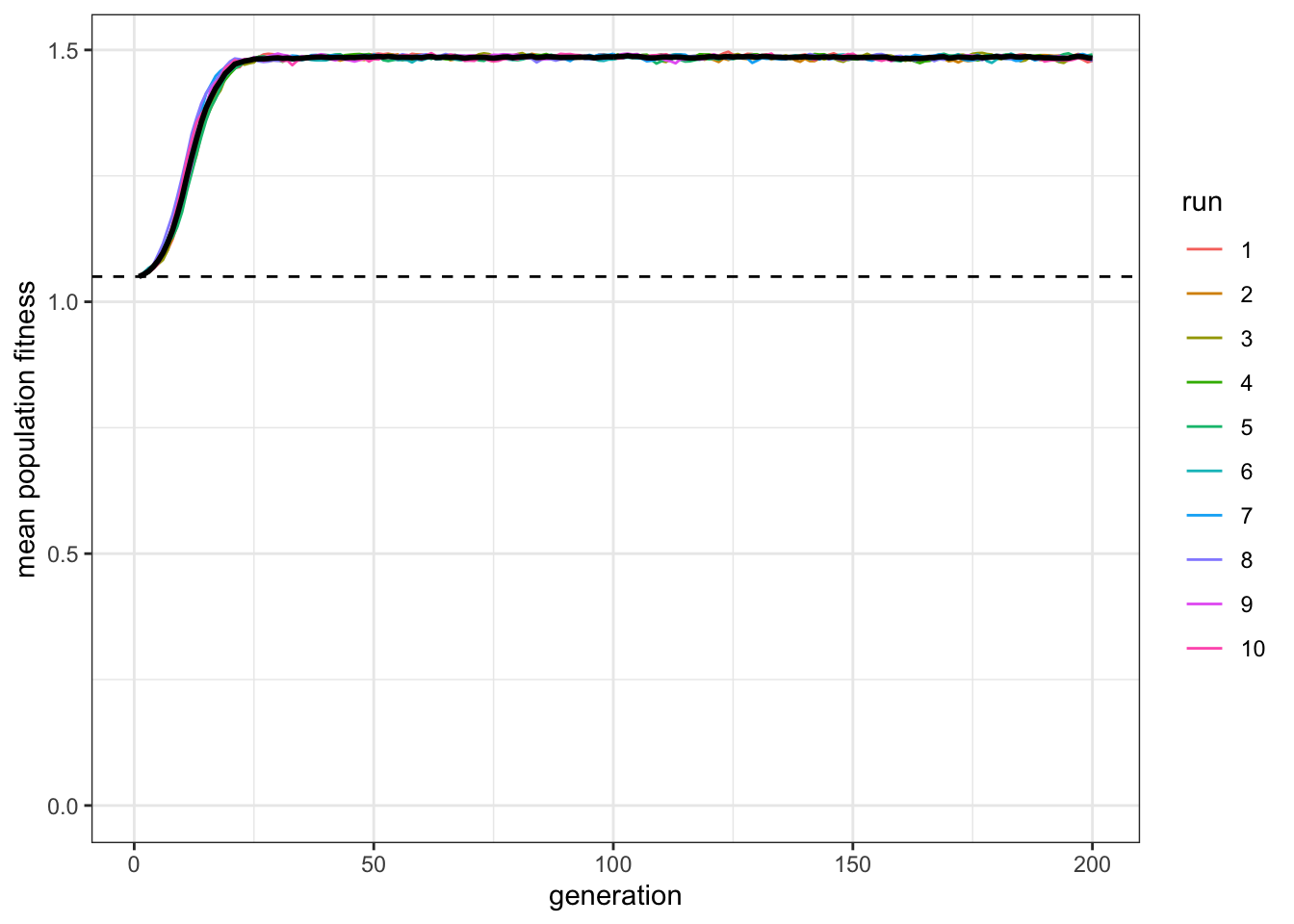
Figure 8.8: Their average fitness (black line) is now much higher than that of indiviudal learners (dashed line).
Now the paradox has disappeared: social learners clearly outperform the individual learners after the latter have gone to the trouble of discovering the correct behaviour, and the social learners have higher mean fitness than the individual learning dotted line. (Notice also the oscillations within each run disappeared.) This is just as we would expect. Rogers’ paradox crucially depends on a changing environment. However, nature rarely provides a constant environment. Food sources change location, technology accumulates, languages diverge, and climates change.
8.2 Summary of the model
Rogers’ model is obviously a gross simplification of reality. However, as discussed in earlier chapters, realism is often not the aim of modelling. Models - even simple and grossly unrealistic ones - force us to think through assumptions, and challenge verbal theorising. Rogers’ model is a good example of this. Even though it sounds reasonable that social learning should increase the mean fitness, or adaptation, of a population, in this simple model with these assumptions it does not. We saw one situation in which social learning does increase mean fitness: when environments do not change. This, however, is not very plausible. Environments always change. We therefore need to examine the other assumptions of Rogers’ model. We will do this in the next chapter.
8.3 Further reading
An early example of the claim that social learning is adaptive because it reduces the costs of learning can be found in Boyd and Richerson (1985). Rogers (1988) then challenged this claim, as we have seen in this chapter. In the next chapter we will consider subsequent models that have examined ‘solutions’ to Rogers’ paradox.